今天我们要聊点劲爆的!Anthropic 放大招了,推出了 Claude 3.7 Sonnet,号称是目前他们最聪明的模型,而且还是个混合推理高手。这个新模型不仅反应速度快到飞起,还能进行深入的、一步一步的思考,整个思考过程还会展现给用户看。API 用户甚至可以精细地控制模型“思考”的时间长短,简直不要太灵活!
代码能力大爆发,前端开发者的福音!
Claude 3.7 Sonnet 在代码和前端 Web 开发方面有了质的飞跃。不光如此,他们还同步推出了一个专门为代理型编码准备的命令行工具,叫做 Claude Code。现在 Claude Code 还处于小范围的研究预览阶段,但它已经能让开发者直接从终端把大量工程任务甩给 Claude 去做了!想想都觉得爽!
各种套餐随便用,价格还跟以前一样!
现在,无论是 Free、Pro、Team 还是 Enterprise 这些 Claude 的套餐,统统都能用上 Claude 3.7 Sonnet。Anthropic API、Amazon Bedrock、Google Cloud’s Vertex AI 也都安排上了。只不过,扩展思考模式除了免费版,其他版本都能用。而且,不管是标准模式还是扩展思考模式,Claude 3.7 Sonnet 的价格都跟之前的模型一样,输入 token 3 美元/百万个,输出 token 15 美元/百万个,包括思考用的 token 哦。
实用性爆棚的推理能力
和其他推理模型不太一样,Claude 3.7 Sonnet 的设计理念有点不一样。他们觉得,就像人脑既能快速反应也能深入思考一样,推理应该是顶级模型的一个集成能力,而不是单独的模型。这种统一的方法用起来也更顺手。
Claude 3.7 Sonnet 就很好地体现了这个理念。首先,它既是个普通的 LLM,也是个推理模型:你可以随时选择让它正常回答,也可以让它先好好想想再回答。在标准模式下,Claude 3.7 Sonnet 就是 Claude 3.5 Sonnet 的升级版。在扩展思考模式下,它会在回答之前进行自我反思,从而提升在数学、物理、指令遵循、编码等方面的表现。一般来说,两种模式下的 prompt 方式差不多。
其次,通过 API 使用 Claude 3.7 Sonnet 时,用户还能控制思考的“预算”:你可以告诉 Claude 最多思考 N 个 token,N 的最大值是它的输出限制,也就是 128K 个 token。这样你就能在速度(和成本)与答案质量之间进行权衡了。
再者,在开发推理模型时,他们并没有把重点放在数学和计算机科学竞赛题上,而是更关注实际的应用场景,也就是企业真正会如何使用 LLM。
代码能力简直逆天
早期测试就表明,Claude 在代码能力方面遥遥领先:Cursor 认为,在实际的编码任务中,Claude 再次成为同类最佳,尤其是在处理复杂代码库和高级工具使用方面进步巨大。Cognition 发现,它在规划代码变更和处理全栈更新方面远胜于其他模型。Vercel 强调了 Claude 在复杂代理工作流程中的卓越精度,而 Replit 已经成功地利用 Claude 从头开始构建复杂的 Web 应用程序和仪表板,而其他模型早就卡壳了。Canva 的评估表明,Claude 始终能够生成可以直接上线的、设计感一流的代码,而且大大减少了错误。
Claude 3.7 Sonnet 在 SWE-bench Verified(一个评估 AI 模型解决实际软件问题的能力的基准)上取得了最先进的性能。
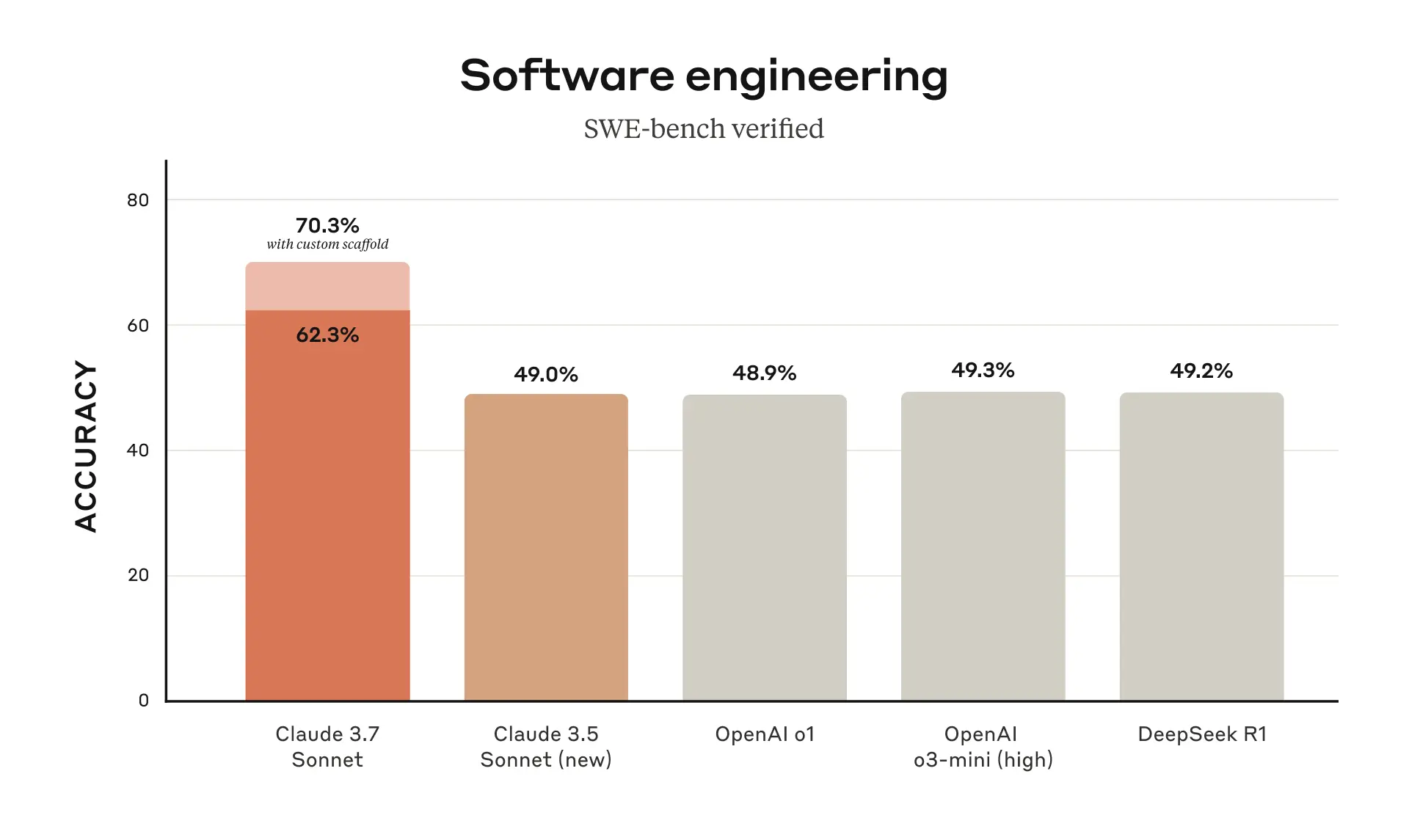
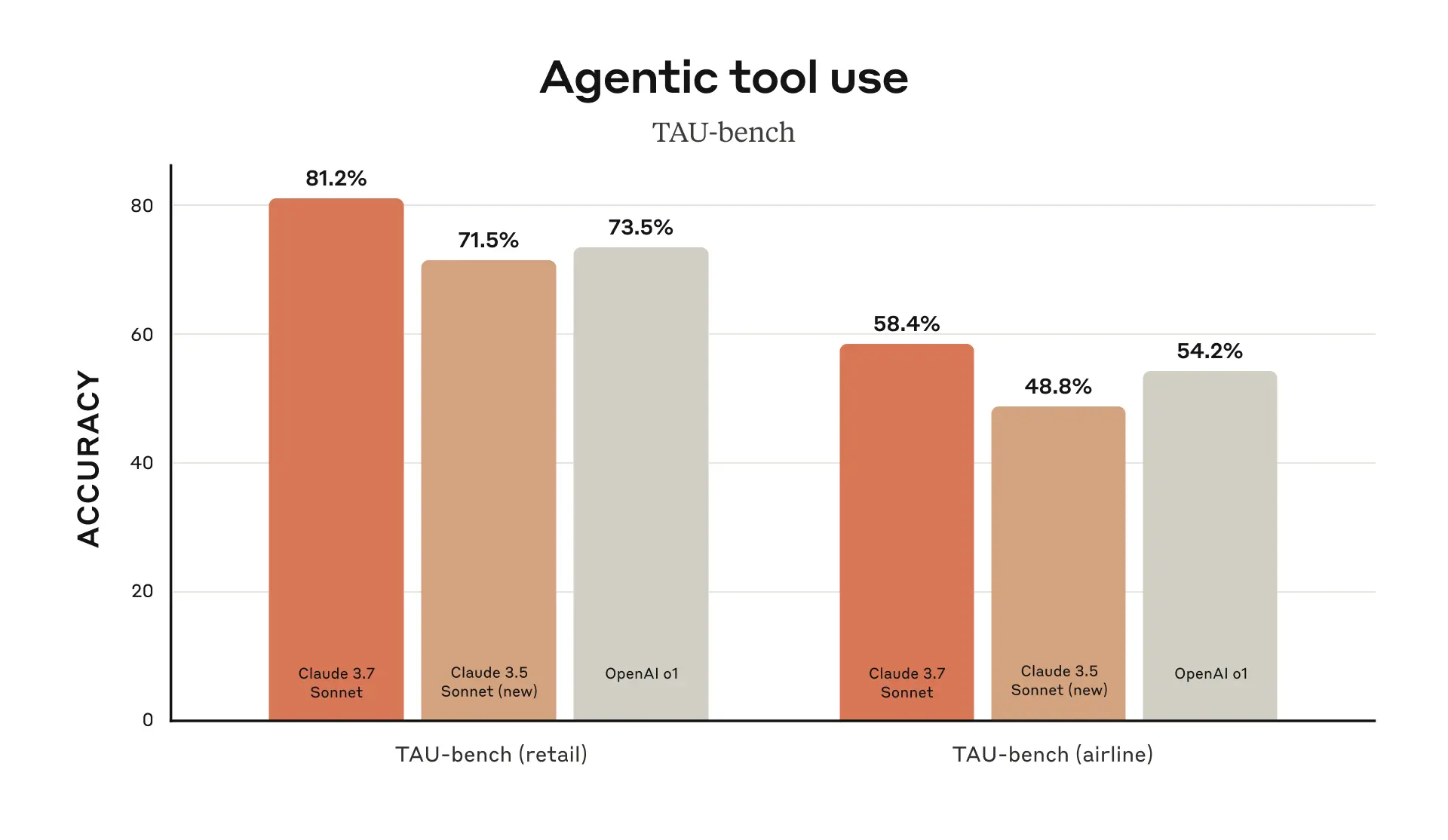
Claude 3.7 Sonnet 在 TAU-bench 上同样表现出色,TAU-bench 是一个测试 AI 代理在复杂的实际任务中与用户和工具进行交互的框架。
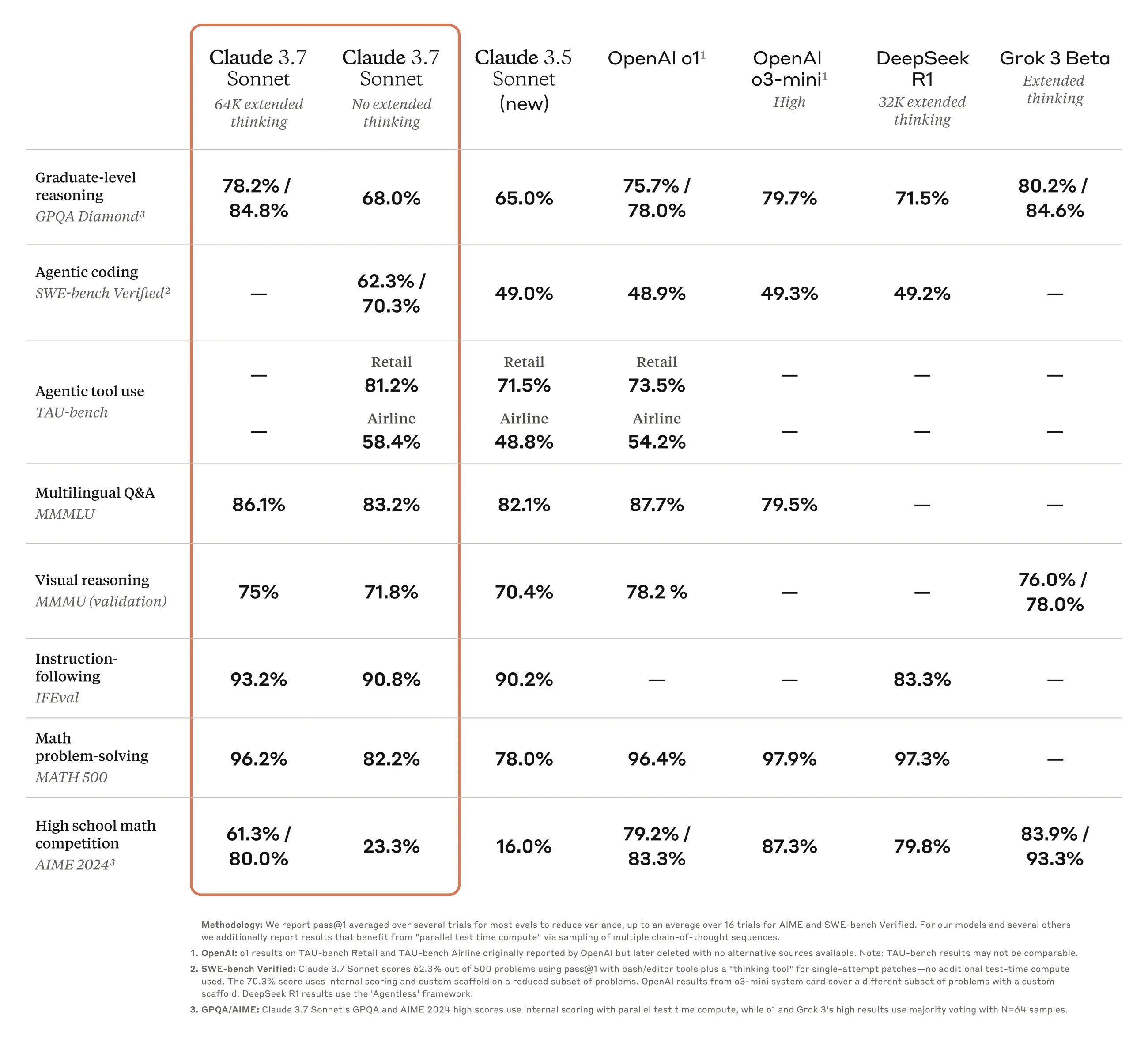
Claude 3.7 Sonnet 在指令遵循、一般推理、多模态能力和代理型编码方面表现出色,扩展思考模式尤其增强了数学和科学方面的能力。除了传统的基准测试外,它甚至在宝可梦游戏测试中也优于所有之前的模型。
Claude Code:代码界的超级助手
自 2024 年 6 月以来,Sonnet 一直是全球开发者的首选模型。今天,他们通过推出 Claude Code(他们的第一个代理型编码工具)的有限研究预览版,进一步赋能开发者。
Claude Code 是一个积极的协作者,它可以搜索和阅读代码,编辑文件,编写和运行测试,提交代码并将其推送到 GitHub,以及使用命令行工具,而且每一步都会让你知情。
Claude Code 还是个早期产品,但它已经成为他们团队不可或缺的工具,尤其是在测试驱动开发、调试复杂问题和大规模重构方面。在早期测试中,Claude Code 可以在一次通过中完成通常需要 45 分钟以上手工完成的任务,从而缩短开发时间和开销。
在接下来的几周内,他们计划根据使用情况不断改进它:提高工具调用可靠性,增加对长时间运行命令的支持,改进应用程序内渲染,并扩展 Claude 自身对其功能的理解。
他们推出 Claude Code 的目标是更好地了解开发者如何使用 Claude 进行编码,从而为未来的模型改进提供信息。通过参与这个预览版,你将可以访问他们用来构建和改进 Claude 的强大工具,并且你的反馈将直接影响它的未来。
在你的代码库上与 Claude 一起工作
他们还改进了 Claude.ai 上的编码体验。他们的 GitHub 集成现在已在所有 Claude 计划中提供,使开发者能够将他们的代码仓库直接连接到 Claude。
Claude 3.7 Sonnet 是他们迄今为止最好的编码模型。凭借对你的个人、工作和开源项目的更深入理解,它将成为一个更强大的合作伙伴,可以帮助你修复错误、开发功能以及构建最重要的 GitHub 项目的文档。
负责任地构建
他们对 Claude 3.7 Sonnet 进行了广泛的测试和评估,并与外部专家合作,以确保它符合他们的安全性、安全性和可靠性标准。与之前的模型相比,Claude 3.7 Sonnet 也能更细致地区分有害和良性请求,从而减少了 45% 的不必要拒绝。
该版本的系统卡涵盖了几个类别中的新安全结果,详细分析了他们的负责任的扩展策略评估,其他 AI 实验室和研究人员可以将其应用于他们的工作。该卡还解决了计算机使用带来的新兴风险,特别是 prompt 注入攻击,并解释了他们如何评估这些漏洞以及如何训练 Claude 来抵御和减轻它们。此外,它还研究了推理模型可能带来的安全益处:理解模型如何做出决策的能力,以及模型推理是否真正值得信赖和可靠。阅读完整的系统卡以了解更多信息。
展望未来
Claude 3.7 Sonnet 和 Claude Code 标志着 AI 系统朝着真正增强人类能力的方向迈出了重要一步。凭借其深入推理、自主工作和有效协作的能力,它们使我们更接近于一个 AI 丰富和扩展人类可以实现的目标的未来。

他们很高兴你能探索这些新功能,并期待看到你用它们创造什么。与往常一样,他们欢迎你的反馈,因为他们会继续改进和发展他们的模型。