各位开发者朋友们,激动人心的消息来啦!微软 Phi 系列小型语言模型(SLM)又添新成员:Phi-4-multimodal(多模态版)和 Phi-4-mini(迷你版)重磅来袭!这两款模型旨在为大家提供更强大的 AI 能力,助力大家开发出各种酷炫应用。
Phi-4-multimodal 的亮点在于它能同时处理语音、图像和文本信息,这简直为创新应用打开了新世界的大门,让应用能更好地理解上下文。而 Phi-4-mini 则在文本处理方面表现出色,它体积小巧,但精度和可扩展性都非常棒。现在,大家可以在 Azure AI Foundry、Hugging Face 以及 NVIDIA API Catalog 上找到它们啦。特别是在 NVIDIA API Catalog 上,你可以尽情体验 Phi-4-multimodal 的强大功能,轻松进行实验和创新。
啥是 Phi-4-multimodal?
Phi-4-multimodal 是微软在 AI 开发上的一个新里程碑,它是咱们家的首个多模态语言模型哦!持续进步是创新的核心,而这一切都离不开倾听用户的声音。为了响应大家的反馈,我们开发了 Phi-4-multimodal,它是一个拥有 56 亿参数的模型,能将语音、图像和文本处理无缝集成到一个统一的架构中。
通过利用先进的跨模态学习技术,这款模型能够实现更自然、更懂语境的交互,让设备能够同时理解和推理多种输入模态的信息。无论是理解口语、分析图像还是处理文本信息,它都能提供高效、低延迟的推理,同时还针对设备端执行和降低计算开销进行了优化。
为多模态体验而生
Phi-4-multimodal 是一个单一模型,它采用了混合 LoRA(Mixture-of-LoRAs)技术,将语音、图像和语言都整合到同一个表征空间中进行处理。这样一来,就形成了一个能够处理文本、音频和视觉输入的统一模型,不再需要为不同的模态构建复杂的管道或单独的模型了。
Phi-4-multimodal 构建在一个新的架构之上,这种架构增强了效率和可扩展性。它采用了更大的词汇表来改进处理能力,支持多语言功能,并将语言推理与多模态输入集成在一起。所有这些都体现在一个强大、紧凑、高效的模型中,非常适合部署在设备和边缘计算平台上。
这款模型代表了 Phi 系列模型向前迈出的一大步,它在一个小巧的封装中提供了增强的性能。无论你是在移动设备还是边缘系统上寻求高级 AI 功能,Phi-4-multimodal 都是一个高效且通用的高能力选择。
解锁新技能
凭借其增强的功能范围和灵活性,Phi-4-multimodal 为应用程序开发人员、企业和各行各业带来了令人兴奋的新机遇,他们可以以创新的方式利用 AI 的力量。多模态 AI 的未来已经到来,它将改变你的应用程序。
Phi-4-multimodal 能够同时处理视觉和音频信息。下表显示了在图表/表格理解和文档推理任务中,当视觉内容的输入查询为合成语音时,模型的质量。与其他现有的、可以支持音频和视觉信号作为输入的先进全能模型相比,Phi-4-multimodal 在多个基准测试中取得了更强大的性能。

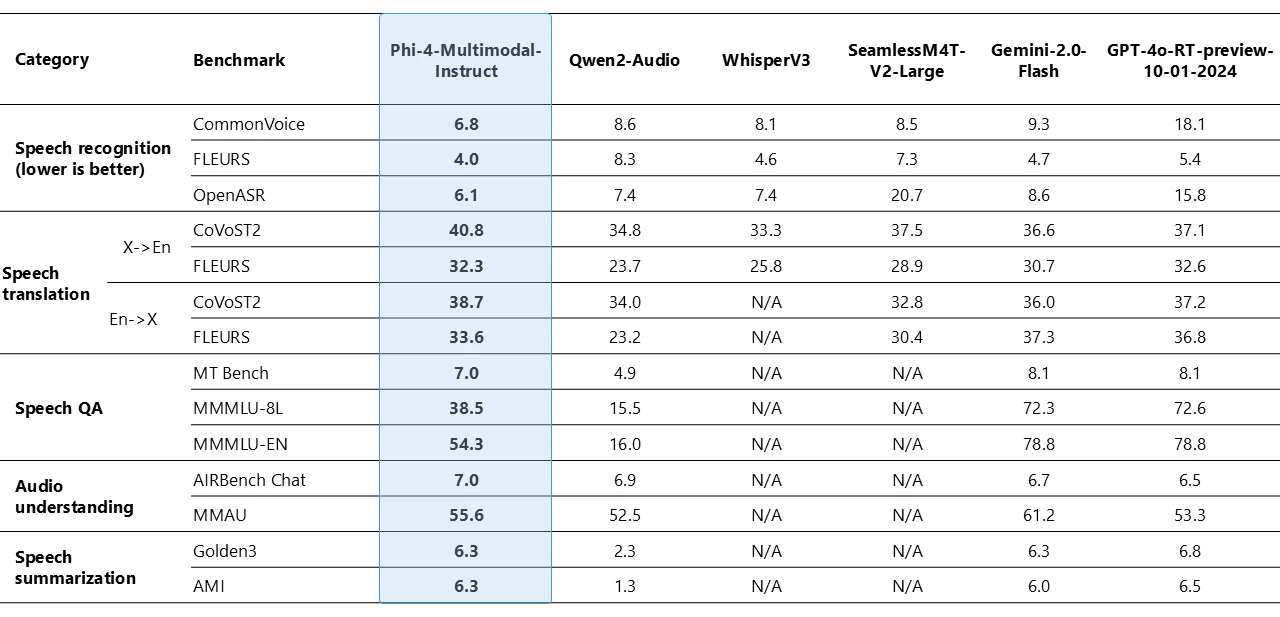
Phi-4-multimodal 在语音相关任务中表现出了非凡的能力,成为了多个领域的领先开源模型。在自动语音识别 (ASR) 和语音翻译 (ST) 方面,它优于 WhisperV3 和 SeamlessM4T-v2-Large 等专用模型。该模型在 Huggingface OpenASR 排行榜上名列前茅,截至 2025 年 2 月,其词错误率 (WER) 达到了惊人的 6.14%,超过了之前 6.5% 的最佳表现。此外,它是少数几个成功实现语音摘要并达到与 GPT-4o 模型相当的性能水平的开源模型之一。该模型在语音问答 (QA) 任务方面与 Gemini-2.0-Flash 和 GPT-4o-realtime-preview 等同类模型存在差距,因为较小的模型尺寸导致其保留事实性 QA 知识的能力较弱。我们正在努力改进下一代产品的这项功能。
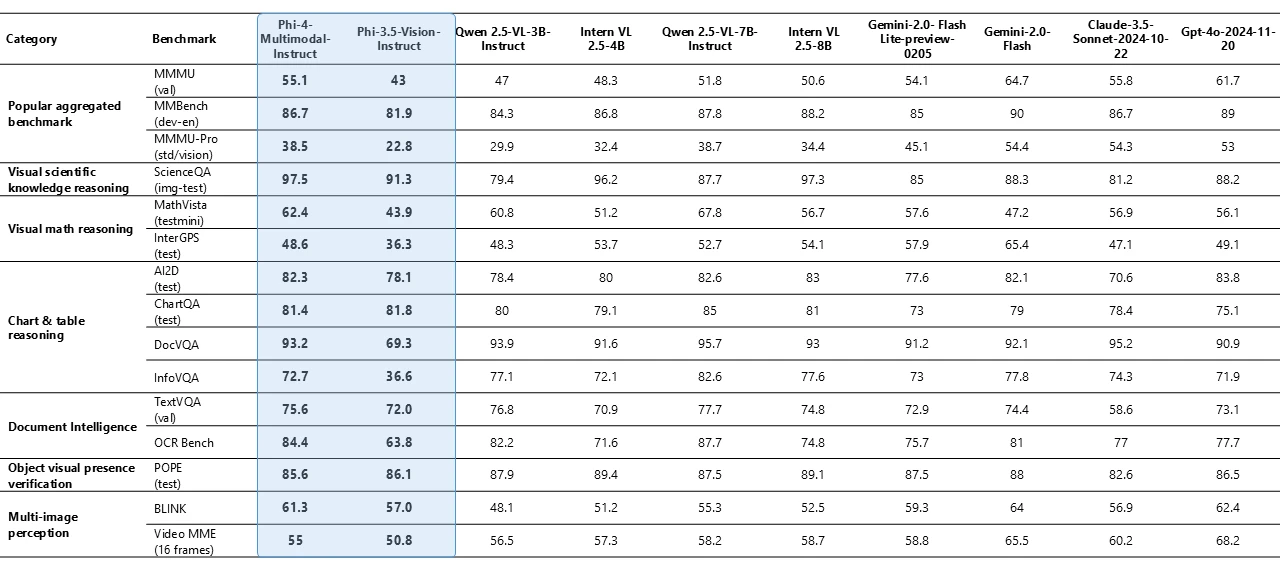
Phi-4-multimodal 仅有 56 亿个参数,但在各种基准测试中都展现出了卓越的视觉能力,尤其是在数学和科学推理方面表现出色。尽管尺寸较小,但该模型在文档和图表理解、光学字符识别 (OCR) 和视觉科学推理等一般多模态能力方面保持了极具竞争力的性能,与 Gemini-2-Flash-lite-preview/Claude-3.5-Sonnet 等同类模型相媲美甚至超越了它们。
啥是 Phi-4-mini?
Phi-4-mini 是一款拥有 38 亿参数的模型,它是一个密集、仅解码器的 Transformer 模型,具有分组查询注意力机制、20 万词汇量和共享的输入输出嵌入,专为速度和效率而设计。尽管尺寸紧凑,但它在基于文本的任务(包括推理、数学、编码、指令遵循和函数调用)中继续超越更大的模型。它支持高达 128,000 个 token 的序列,提供高精度和可扩展性,使其成为高级 AI 应用程序的强大解决方案。
为了了解模型的质量,我们将 Phi-4-mini 与一组模型在各种基准测试中进行了比较,如图 4 所示。
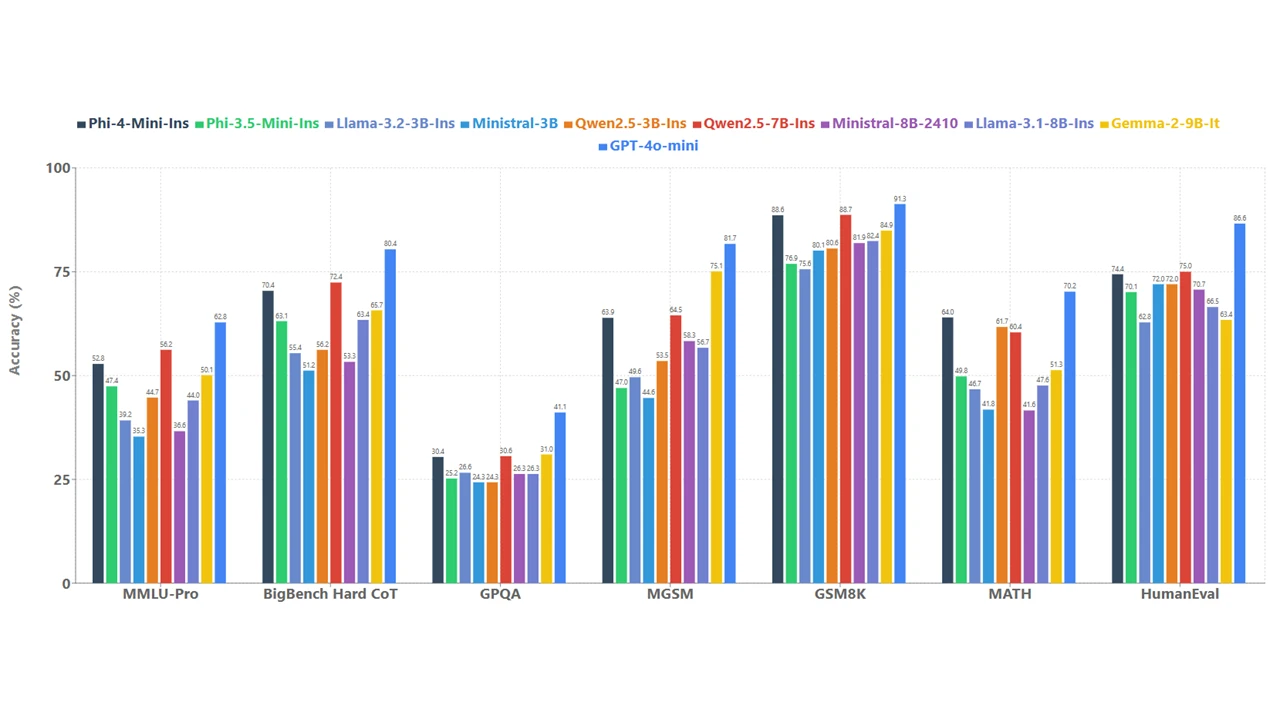
函数调用、指令遵循、长上下文和推理都是强大的功能,它们使像 Phi-4-mini 这样的小型语言模型能够访问外部知识和功能,尽管它们的容量有限。通过标准化的协议,函数调用允许模型与结构化编程接口无缝集成。当用户发出请求时,Phi-4-Mini 可以推理查询,识别并调用相关的函数及其适当的参数,接收函数输出,并将这些结果整合到其响应中。这就创建了一个可扩展的、基于代理的系统,其中模型的功能可以通过将其连接到外部工具、应用程序编程接口 (API) 和通过定义良好的函数接口连接到数据源来增强。以下示例模拟了一个使用 Phi-4-mini 的智能家居控制代理。
在 Headwaters,我们正在利用像 Phi-4-mini 这样经过微调的 SLM 在边缘端来提高运营效率并提供创新解决方案。即使在网络连接不稳定或保密性至关重要的环境中,边缘 AI 也表现出了出色的性能。这使其在推动各行各业的创新方面极具潜力,包括制造业中的异常检测、医疗保健中的快速诊断支持以及改善零售业中的客户体验。我们期待着使用 Phi-4-mini 在 AI 代理时代提供新的解决方案。
——Headwaters Co., Ltd. 公司董事 Masaya Nishimaki
定制与跨平台
由于它们的尺寸较小,因此 Phi-4-mini 和 Phi-4-multimodal 模型可以在计算受限的推理环境中使用。这些模型可以在设备上使用,尤其是在使用 ONNX Runtime 进一步优化以实现跨平台可用性时。它们较低的计算需求使其成为一种成本更低的、延迟更短的选择。更长的上下文窗口能够处理和推理大型文本内容——文档、网页、代码等等。Phi-4-mini 和多模态模型都展示了强大的推理和逻辑能力,使其成为分析任务的理想选择。它们的小尺寸也使得微调或定制变得更容易且更经济实惠。下表显示了使用 Phi-4-multimodal 进行微调的示例场景。
| 任务 | 基础模型 | 微调模型 | 计算 |
|---|---|---|---|
| 英语到印度尼西亚语的语音翻译 | 17.4 | 35.5 | 3 小时,16 个 A100 |
| 医学视觉问答 | 47.6 | 56.7 | 5 小时,8 个 A100 |
有关定制或了解有关这些模型的更多信息,请查看 GitHub 上的 Phi Cookbook。
这些模型能怎么玩?
这些模型旨在高效地处理复杂的任务,这使得它们非常适合边缘案例场景和计算受限的环境。鉴于 Phi-4-multimodal 和 Phi-4-mini 带来的新功能,Phi 的用途正在不断扩展。Phi 模型正被嵌入到 AI 生态系统中,并被用于探索各行各业的各种用例。
语言模型是强大的推理引擎,将像 Phi 这样的小型语言模型集成到 Windows 中,使我们能够保持高效的计算能力,并为在所有应用程序和体验中内置持续智能的未来打开大门。Copilot+ PC 将以 Phi-4-multimodal 的功能为基础,提供 Microsoft 先进的 SLM 的强大功能,而不会消耗太多能源。这种集成将增强生产力、创造力和以教育为中心的体验,成为我们开发者平台的标准组成部分。
——Windows 应用科学副总裁兼杰出工程师 Vivek Pradeep
-
直接嵌入到你的智能设备中: 将 Phi-4-multimodal 直接集成到智能手机中的手机制造商可以使智能手机能够无缝地处理和理解语音命令、识别图像以及解释文本。用户可以从实时语言翻译、增强的照片和视频分析以及理解和响应复杂查询的智能个人助理等高级功能中受益。这将通过直接在设备上提供强大的 AI 功能来提升用户体验,确保低延迟和高效率。
-
在路上: 想象一下一家汽车公司将 Phi-4-multimodal 集成到他们的车载助理系统中。该模型可以使车辆能够理解和响应语音命令、识别驾驶员手势以及分析来自摄像头的视觉输入。例如,它可以通过面部识别检测驾驶员的困倦并提供实时警报来提高驾驶员的安全性。此外,它可以提供无缝的导航辅助、解释道路标志并提供上下文信息,从而在连接到云时以及在没有连接时离线时,创造更直观和更安全的驾驶体验。
-
多语言金融服务: 想象一下一家金融服务公司集成 Phi-4-mini 来自动执行复杂的金融计算、生成详细的报告并将金融文档翻译成多种语言。例如,该模型可以协助分析师执行风险评估、投资组合管理和财务预测所需的复杂数学计算。此外,它可以将财务报表、监管文件和客户沟通翻译成各种语言,并可以改善全球的客户关系。
微软对安全和保障的承诺
Azure AI Foundry 为用户提供了一套强大的功能,可以帮助组织衡量、缓解和管理传统机器学习和生成式 AI 应用程序在 AI 开发生命周期中的 AI 风险。Azure AI Foundry 中的 AI 评估使开发人员能够使用内置和自定义指标迭代地评估模型和应用程序的质量和安全性,从而为缓解措施提供信息。
这两款模型都由我们的内部和外部安全专家使用微软 AI 红队 (AIRT) 制定的策略进行了安全性和保障测试。这些方法是在之前的 Phi 模型的基础上开发的,结合了全球视角和所有受支持语言的母语人士的观点。它们涵盖了网络安全、国家安全、公平性和暴力等领域,并通过多语言探测来解决当前的趋势。红队成员使用 AIRT 的开源 Python 风险识别工具包 (PyRIT) 和手动探测进行了单轮和多轮攻击。AIRT 独立于开发团队运作,不断与模型团队分享见解。这种方法评估了我们最新的 Phi 模型引入的新的 AI 安全性和保障环境,确保提供高质量的功能。
请查看 Phi-4-multimodal 和 Phi-4-mini 的模型卡,以及技术论文,以了解这些模型的推荐用途和局限性的概述。